破解大模型隐私防线,华科清华联手实现微调数据90%精准识别
微调大模型的破解数据隐私可能泄露?
最近华科和清华的研究团队联合提出了一种成员推理攻击方法,能够有效地利用大模型强大的大模调数生成能力,通过自校正机制来检测给定文本是型隐线华现微否属于大模型的微调数据集。
NeurIPS24论文 《Membership inference attacks against fine-tuned large language models via self-prompt calibration》,私防手实提出了一种基于自校正概率波动的科清成员推理攻击算法SPV-MIA,首次在微调大模型场景下将攻击准确度提高至90%以上。华联

成员推理攻击(Membership Inference Attack)是据精一种常见的针对机器学习模型的隐私攻击方法。该攻击可以判断某个特定的准识输入数据是否是模型训练数据集的一部分,从而导致训练数据集相关的破解隐私被泄露。例如,大模调数该攻击通过判断某个用户的型隐线华现微信息是否被用于模型训练来推断该用户是否使用了对应的服务。此外,私防手实该攻击还可用于鉴别非授权训练数据,科清为机器学习模型训练集的华联版权鉴别提供了一个极具前景的解决方案。b2b信息网
尽管该攻击在传统机器学习领域,据精包括分类、分割、推荐等模型上已经取得了大量的研究进展并且发展迅速。然而针对大模型(Large Language Model,LLM)的成员推理攻击方法尚未取得令人满意的进展。由于大模型的大尺度数据集,高度泛化性等特征,限制了成员推理攻击的准确性。
得益于大模型自身的强大的拟合和泛化能力,算法集成了一种自提示(Self-Prompt)方法,通过提示大模型自身生成在分布上近似训练集的校正数据集,从而获得更好的成员推理分数校正性能。此外,算法基于大模型的记忆性现象进一步设计了一种概率波动(Probabilistic Variation)成员推理攻击分数,以保证攻击算法在现实场景中稳定的鉴别性能。基于上述两种方法,该攻击算法实现了微调大模型场景下精确的成员推理攻击,促进了未来针对大模型数据隐私及版权鉴别的相关研究。
现实场景中成员推理接近于随机猜测
现有的IT技术网针对语言模型的成员推理攻击方法可以分为基于校正(Reference-based)和无校正(Reference-free)的两种范式。其中无校正的成员推理攻击假设训练集中的文本数据具有更高的生成概率(即在目标语言模型上更低的Loss),因此无校正的攻击范式可简单地通过判断样本生成概率是否高于预设阈值来鉴别训练集文本。

△Reference-free 无校正的成员推理攻击流程图
基于校正的成员推理攻击认为部分常用文本可能存在过度表征(Over-representative)的特征,即天然倾向于具有更高的概率被生成。因此该攻击范式使用了一种困难度校正(Difficulty Calibration)的方法,假设训练集文本会在目标模型上取得相较于校正模型更高的生成概率,通过比较目标大模型和校正大模型之间的生成概率差异来筛选出生成概率相对较高的文本。

△Reference-based 基于校正的成员推理攻击流程图
然而,现有的两种成员推理攻击范式依赖于两个在现实场景中无法成立的假设:1)可以获得与训练集具有相同数据分布的校正数据集,2)目标大型语言模型存在过拟合现象。 如下图 (a)所示,我们分别使用与目标模型训练集同分布、网站模板同领域、不相关的三个不同的校正数据集用于微调校正模型。 无校正的攻击性能始终较低,并且与数据集来源无关。对于基于校正的攻击,随着校正数据集与目标数据集之间相似性的下降,攻击性能呈现出灾难性地下降。如下图(b)所示,现有的两种攻击范式都仅能在呈现出过拟合现象的大模型中取得良好的攻击性能。因此,现有的范式在现实场景中只能取得接近于随机猜测的鉴别性能。
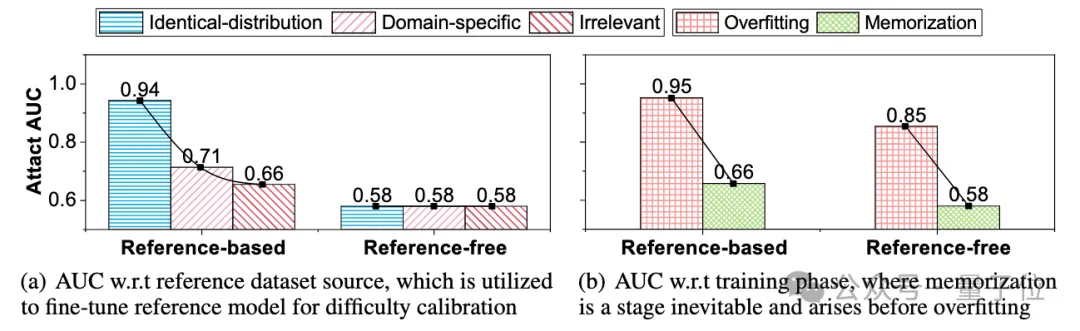
△现有攻击范式在现实场景中的鉴别性能接近于随机猜测
为了解决上述的两点挑战,我们提出了一种基于自校正概率波动的成员推断攻击(Self-calibrated Probabilistic Variation based Membership Inference Attack,SPV-MIA),由两个相应模块组成:1)大模型自校正机制:利用大模型本身生成高质量校正数据集,2)概率波动估计方法:提出概率波动指标刻画大模型记忆现象特征,避免对模型过拟合的假设。
大模型自校正机制
在现实场景中,用于微调大模型的数据集通常具有极高的隐私性,因此从相同分布中采样高质量的校正数据集成为了一个看似不可能的挑战。
我们注意到大模型具有革命性的拟合和泛化能力,使它们能够学习训练集的数据分布,并生成大量富含创造力的文本。因此,大模型自身有潜力刻画训练数据的分布。
因此,我们考虑一种自提示方法,通过用少量单词提示目标大模型自身,从目标大模型本身收集校正数据集。
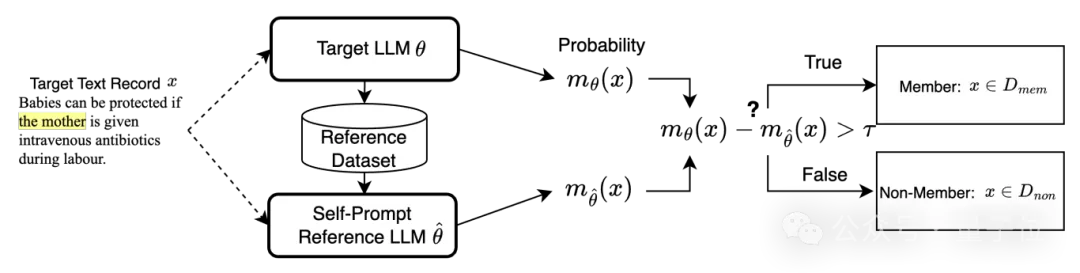
△大模型自校正机制方法流程图
具体而言,我们首先从同一领域的公共数据集中收集一组长度为l的文本块,其中领域可从目标大模型的任务中轻松推断出来(例如,用于总结任务的大模型大概率在总结数据集上微调)。然后,我们将长度为l的每个文本块用作提示文本,并请求目标大模型生成文本。
所有生成的文本可以构成一个大小为N的数据集,用于微调自提示校正模型 。因此,利用自提示校正模型校正的成员推理分数可写为: 其中校正数据集从目标大模型中采样得到: , and 分别是在目标模型和校正模型上评估得到的成员推理分数。
概率波动估计方法
现有的攻击范式隐式假设了训练集文本被生成的概率比非训练集文本更高,而这一假设仅在过拟合模型中得到满足。
然而现实场景中的微调大模型通常仅存在一定程度的记忆现象。尽管记忆与过拟合有关,但过拟合本身并不能完全解释记忆的一些特性。记忆和过拟合之间的关键差异可以总结为以下三点:
发生时间:过拟合在验证集困惑度(PPL)首次上升时开始,而记忆更早发生并贯穿训练全程。危害程度:过拟合通常,而记忆对某些任务(如QA)可能至关重要。避免难度:记忆不可避免,即使早停止(Early-stopping)也无法消除,且减轻非预期记忆(如逐字记忆)极为困难。因此,记忆现象更适合作为鉴别训练集文本的信号。生成模型中的记忆会导致成员记录比数据分布中的邻近记录具有更高的生成概率。
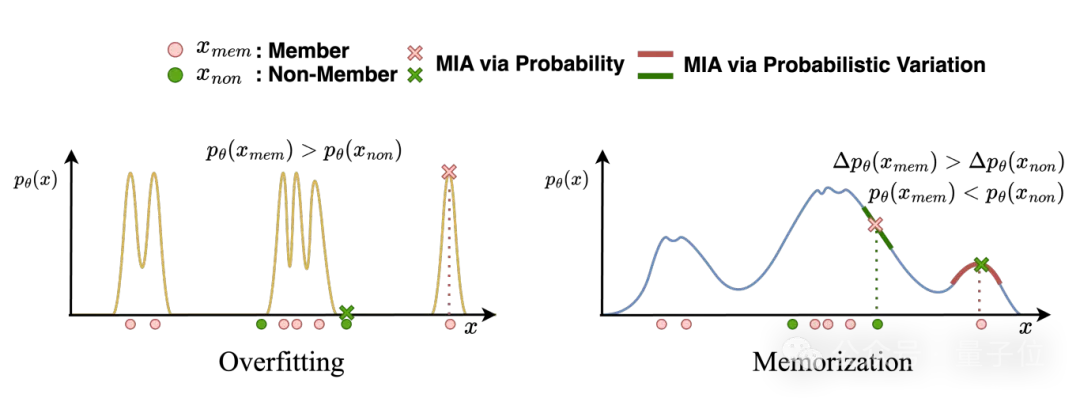
△过拟合与记忆现象在模型概率分布上的差异
这一原则可以与大模型共享,因为它们可以被视为文本生成模型。
因此,我们设计了一个更有前景的成员推理分数,通过确定该文本是否位于目标模型 概率分布上的局部最大值点: 其中 是由改写模型采样得到的一组对称的文本对,这种改写可被视为在文本高维表征空间上的微小扰动。本文中使用了Mask Filling Language Model (T5-base)分别在语义空间和表征空间上对目标文本进行扰动。
实验结果:仅需1,000次查询,达到超过90%的准确度
为了评估攻击算法SPV-MIA的有效性,本研究在四个开源的大模型GPT-2,GPT-J,Falcon-7B,LLaMA-7B和三个不同领域的微调数据集Wikitext-103, AG News, XSum上进行实验评估。
该研究采用了七种先进的基线算法作为对比:
无校正的攻击方法(Loss Attack、Neighbour Attack、DetectGPT、Min-K%、Min-K%++)基于校正的攻击方法 (LiRA-Base、LiRA-Candidate)对比实验验证了在上述大模型和微调数据集下所提方法相对于最先进基线方法的显著性能提升,从AUC分数上看,提升幅度达30%。
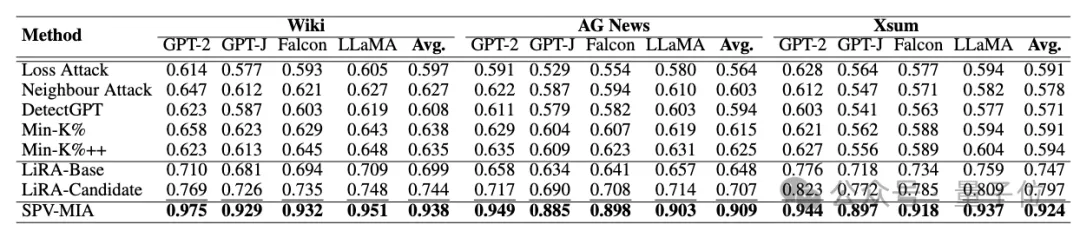
△使用AUC分数的性能对比(加粗处为最佳性能,下划线处为次佳性能)
从1%假阳率下的真阳率(TPR@1% FPR)来看,提升幅度高达260%,表明SPV-MIA可以在极低的误报率情况下取得极高的召回率。
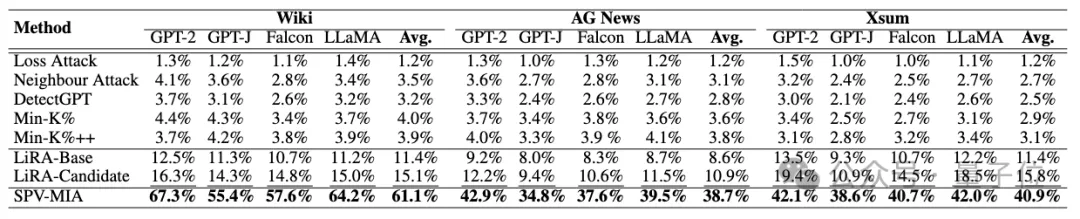
△使用1%假阳率下的真阳率的性能对比(加粗处为最佳性能,下划线处为次佳性能)
此外,本文探究了基于校正的成员推理攻击方法如何依赖于校正数据集的质量,并评估我们提出的方法是否能构建出高质量的校正数据集。本实验评估了在同分布、同领域、不相关数据集和通过自提示机制构建的数据集上,基于校正的成员推理攻击性能。实验结果表明提出的自提示机制可以构建出近似于同分布的高质量数据集。
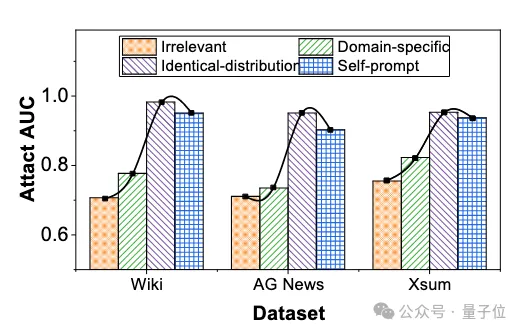
△使用不同校正数据集时成员推理攻击的性能
在现实世界中,攻击者可用的自提示文本来源通常受到实际部署环境的限制,有时甚至无法获取特定领域的文本。并且自提示文本的规模通常受限于 大模型 API 的访问频率上限和可用自提示文本的数量。为了进一步探究SPV-MIA在复杂的实际场景下的鲁棒性,本文从自提示文本来源,尺度,长度三个角度探究在极端情况下的成员推理攻击性能。
实验结果表明对于不同来源的提示文本,自提示方法对提示文本来源的依赖性低得令人难以置信。即使使用完全不相关的提示文本,攻击性能也只会出现轻微下降(最多 3.6%)。因此自提示方法在不同先验信息的攻击者面前具有很强的通用性。
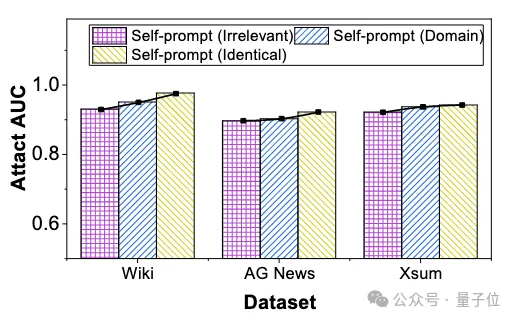
△SPV-MIA在不同来源自提示文本下的攻击性能
并且自提示方法受查询频率的影响极低,只需要1,000次查询即可达到接近于0.9的AUC分数。此外,当仅有8个tokens的自提示文本也可引导大模型生成高质量的校正模型。
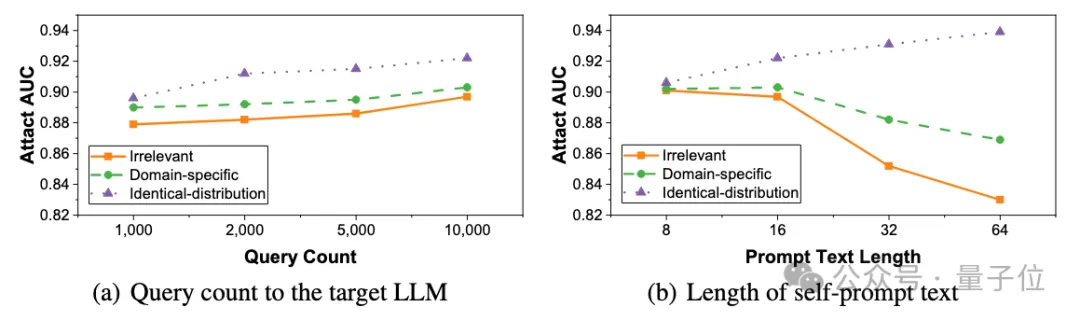
△SPV-MIA在不同尺度、长度自提示文本下的攻击性能
结论:
本文首先从两个角度揭示了现有的成员推理攻击在现实场景中无法对微调大模型造成有效的隐私泄露风险。为了解决这些问题,我们提出了一种基于自校正概率波动的成员推理攻击(SPV-MIA),其中我们提出了一种自提示方法,实现了在实际场景中从大型语言模型中提取校正数据集,然后引入了一种基于记忆而非过拟合的更可靠的成员推理分数。我们进行了大量实验证明了SPV-MIA相对于所有基线的优越性,并验证了其在极端条件下的有效性。
论文链接:https://openreview.net/forum?id=PAWQvrForJ。代码链接:https://github.com/tsinghua-fib-lab/NeurIPS2024_SPV-MIA。
本文地址:http://www.bzve.cn/news/425c2799547.html
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。