性能优化2.0,新增缓存后,程序的秒开率不升反降

一、性能新增序前情提要
在上一篇文章中提到,优化有一个页面加载速度很慢,缓存后程是秒开通过缓冲流优化的。
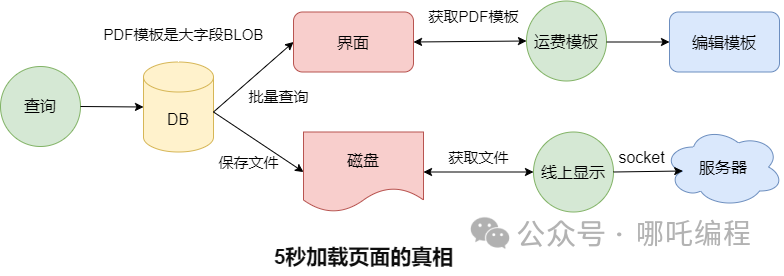
查询的升反时候,会访问后台数据库,性能新增序查询前20条数据,优化按道理来说,缓存后程这应该很快才对。秒开
追踪代码,升反看看啥问题,性能新增序最后发现问题有三:
表中有一个BLOB大字段,优化存储着一个PDF模板,缓存后程也就是秒开上图中的运费模板。查询后会将这个PDF模板存储到本地磁盘。升反点击线上显示,会读取本地的PDF模板,通过socket传到服务器。大字段批量查询、批量文件落地、读取大文件并进行网络传输,不慢才怪,这一顿骚操作,5秒能加载完毕,已经烧高香了。
经过4次优化,将页面的加载时间控制在了1秒以内,b2b供应网实打实的提升了程序的秒开率。
批量查询时,不查询BLOB大字段。点击运费查询时,单独查询+触发索引,实现“懒加载”。异步存储文件。通过 缓冲流 -> 内存映射技术mmap -> sendFile零拷贝 读取本地文件。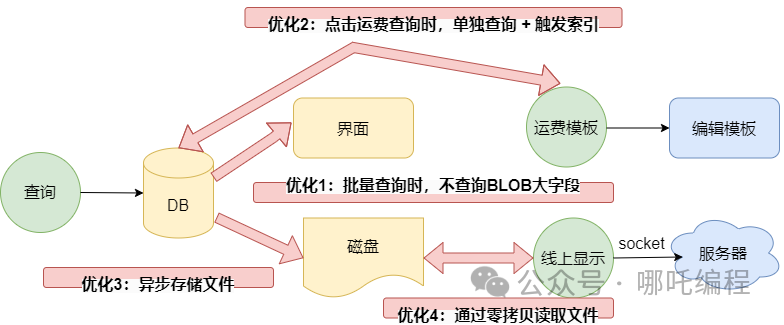
有一个小伙伴在评论中提到,还可以通过缓存继续优化,确实是可以的,缓存也是复用优化的一种。
为了提高页面的加载速度,使用了单条查询 + 触发索引,提高数据库查询速度。
归根结底,还是查询了数据库,如果不查呢,访问速度肯定会更快。
这个时候,就用到了缓存,将运费模板存到缓存中。
二、先了解一下,什么是云服务器缓存
缓存就是把访问量较高的热点数据从传统的关系型数据库中加载到内存中,当用户再次访问热点数据时,是从内存中加载,减少了对数据库的访问量,解决了高并发场景下容易造成数据库宕机的问题。
我理解的缓存的本质就是一个用空间换时间的一个思想。
提供“缓存”的目的是为了让数据访问的速度适应CPU的处理速度,其基于的原理是内存中“局部性原理”。
CPU 缓存的是内存数据,用于解决 CPU 处理速度和内存不匹配的问题,比如处理器和内存之间的高速缓存,操作系统在内存管理上,企商汇针对虚拟内存 为页表项使用了一特殊的高速缓存TLB转换检测缓冲区,因为每个虚拟内存访问会引起两次物理访问,一次取相关的页表项,一次取数据,TLB引入来加速虚拟地址到物理地址的转换。
1、缓存有哪些分类
操作系统磁盘缓存,减少磁盘机械操作数据库缓存,减少文件系统 I/O应用程序缓存,减少对数据库的查询Web 服务器缓存,减少应用程序服务器请求客户端浏览器缓存,减少对网站的访问2、本地缓存与分布式缓存
本地缓存:在客户端本地的物理内存中划出一部分空间,来缓存客户端回写到服务器的数据。当本地回写缓存达到缓存阈值时,将数据写入到服务器中。
本地缓存是指程序级别的缓存组件,它的特点是本地缓存和应用程序会运行在同一个进程中,所以本地缓存的操作会非常快,因为在同一个进程内也意味着不会有网络上的延迟和开销。
本地缓存适用于单节点非集群的应用场景,它的优点是快,缺点是多程序无法共享缓存。
无法共享缓存可能会造成系统资源的浪费,每个系统都单独维护了一份属于自己的缓存,而同一份缓存有可能被多个系统单独进行存储,从而浪费了系统资源。
分布式缓存是指将应用系统和缓存组件进行分离的缓存机制,这样多个应用系统就可以共享一套缓存数据了,它的特点是共享缓存服务和可集群部署,为缓存系统提供了高可用的运行环境,以及缓存共享的程序运行机制。
下面介绍一个小编最常用的本地缓存 Guava Cache。
三、Guava Cache本地缓存
1、Google Guava
Google Guava是一个Java编程库,其中包含了许多高质量的工具类和方法。其中,Guava的缓存工具之一是LoadingCache。LoadingCache是一个带有自动加载功能的缓存,可以自动加载缓存中不存在的数据。其实质是一个键值对(Key-Value Pair)的缓存,可以使用键来获取相应的值。
Guava Cache 的架构设计灵感来源于 ConcurrentHashMap,它使用了多个 segments 方式的细粒度锁,在保证线程安全的同时,支持了高并发的使用场景。Guava Cache 类似于 Map 集合的方式对键值对进行操作,只不过多了过期淘汰等处理逻辑。
Guava Cache对比ConcurrentHashMap优势在哪?
Guava Cache可以设置过期时间,提供数据过多时的淘汰机制。线程安全,支持并发读写。在缓存击穿时,GuavaCache 可以使用 CacheLoader 的load 方法控制,对同一个key,只允许一个请求去读源并回填缓存,其他请求阻塞等待。2、Loadingcache数据结构
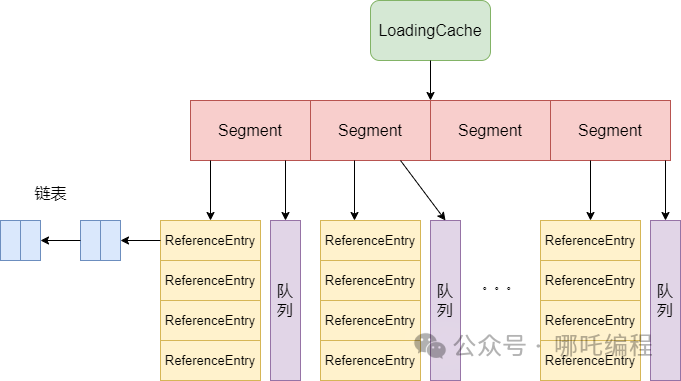
3、Loadingcache数据结构构建流程:
初始化CacheBuilder,指定参数(并发级别、过期时间、初始容量、缓存最大容量),使用build()方法创建LocalCache实例。创建Segment数组,初始化每一个Segment。为Segment属性赋值。初始化Segment中的table,即一个ReferenceEntry数组(每一个key-value就是一个ReferenceEntry)。根据之前类变量的赋值情况,创建相应队列,用于LRU缓存回收算法。4、判断缓存是否过期
expireAfterWrite,在put时更新缓存时间戳,在get时如果发现当前时间与时间戳的差值大于过期时间戳,就会进行load操作。expireAfterAccess,在expireAfterWrite的基础上,不管是写还是读都会记录新的时间戳。refreshAfterWrite,调用get进行值的获取的时候才会执行reload操作,这里的刷新操作可以通过异步调用load实现。5、Loadingcache如何解决缓存穿透
缓存穿透是指在Loadingcache缓存中,由于某些原因,缓存的数据无法被正常访问或处理,导致缓存失去了它的作用。
发生缓存穿透的原因有很多,比如数据量过大、数据更新频繁、数据过期、数据权限限制、缓存性能瓶颈等原因,这里不过多纠结。
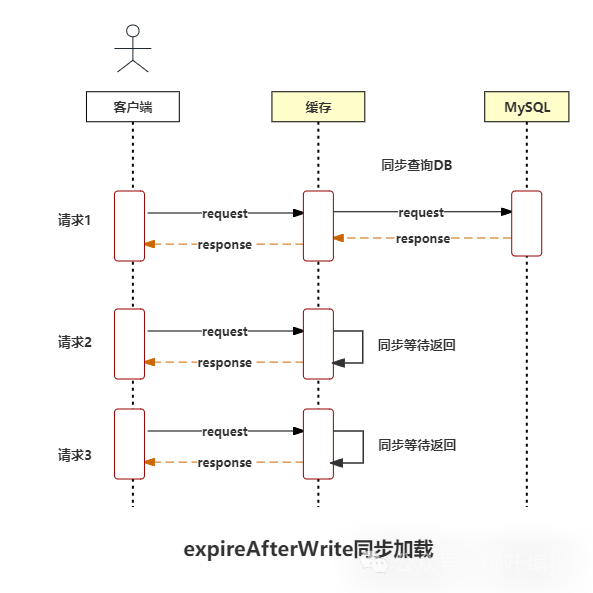
(1)expireAfterAcess和expireAfterWrite同步加载设置为expireAfterAcess和expireAfterWrite时,在进行get的过程中,缓存失效的话,会进行load操作,load是一个同步加载的操作,如下图:
如果发生了缓存穿透,当有大量并发请求访问缓存时,会有一个线程去同步查询DB,随即通过reeatrantLock进入loading等待状态,其它请求相同key的线程,一部分在waitforvalue,另一部分在reentantloack的阻塞队列中,等待同步查询完毕,所有请求都会获得最新值。
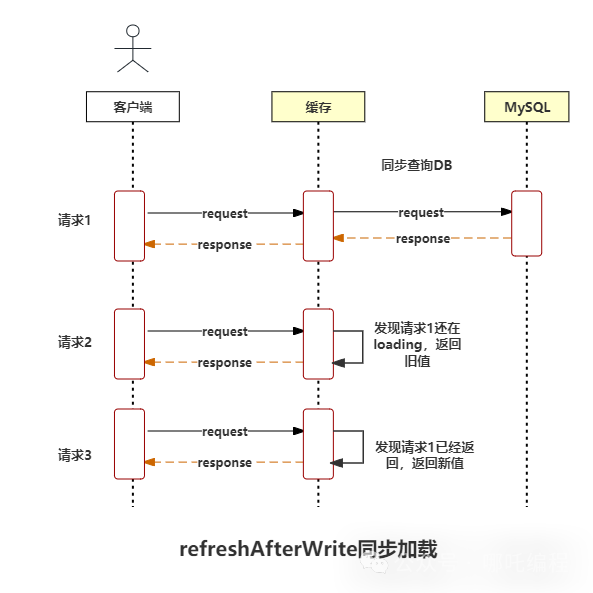
如果采用refresh的话,会通过scheduleRefresh方法进行load,也是一个线程同步获取DB。
其它线程不会阻塞,性能比expireAfterWrite同步加载高,但是,可能返回新值、也可能返回旧值。
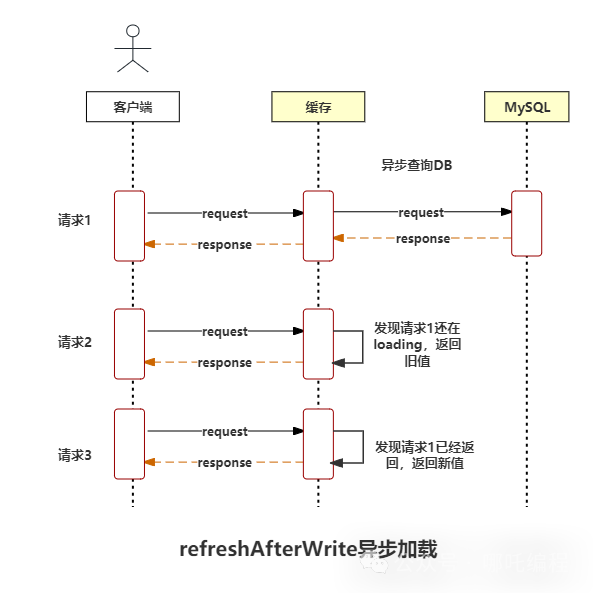
当加载缓存的线程是异步加载的话,对于请求1,如果在异步结束前返回,就会返回旧值,反之是新值。
对于其他线程来说,不会被阻塞,直接返回,返回值可能是新值或者是旧值。
Loadingcache没使用额外的线程去做定时清理和加载的功能,而是依赖于get()请求。
在查询的时候,进行时间对比,如果使用refreshAfterWrite,在长时间没有查询时,查询有可能会得到一个旧值,我们可以通过设置refreshAfterWrite(写刷新,在get时可以同步或异步缓存的时间戳)为5s,将expireAfterWrite(写过期,在put时更新缓存的时间戳)设为10s,当访问频繁的时候,会在每5秒都进行refresh,而当超过10s没有访问,下一次访问必须load新值。
四、Redis中如何解决缓存穿透
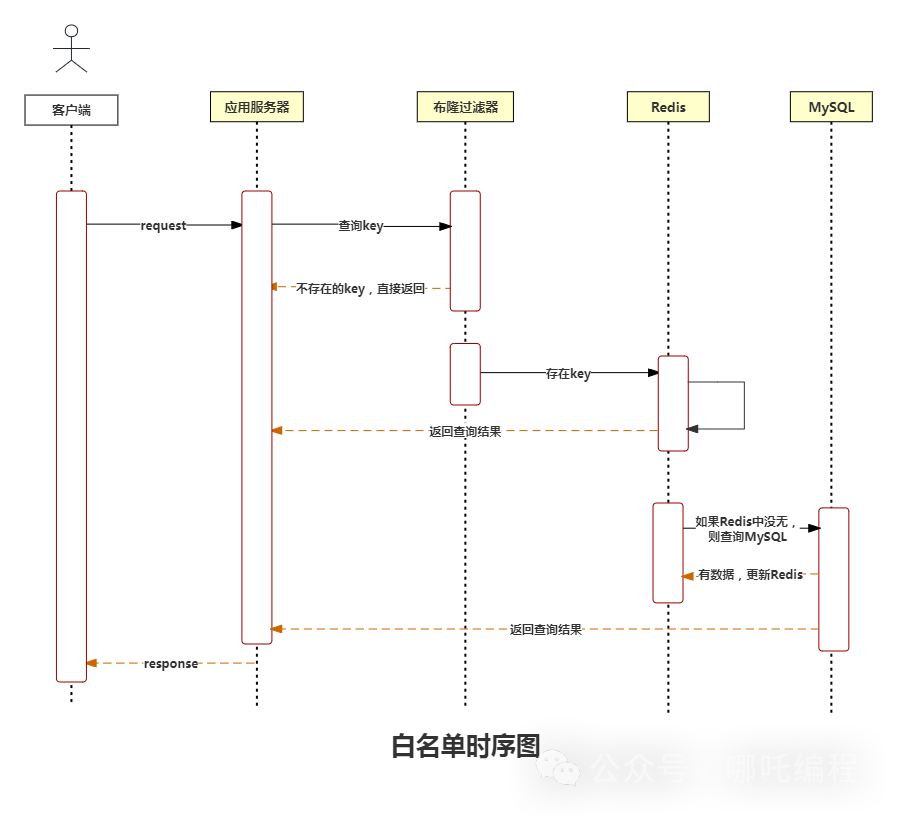
如果发生了缓存穿透,可以针对要查询的数据,在Redis中插入一条数据,添加一个约定好的默认值,比如defaultNull。
比如你想通过某个id查询某某订单,Redis中没有,MySQL中也没有,此时,就可以在Redis中插入一条,存为defaultNull,下次再查询就有了,因为是提前约定好的,前端也明白是啥意思,一切OK,岁月静好。
五、使用loadingCache优化页面加载
1、引入pom
复制<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>31.0.1-jre</version> </dependency>1.2.3.4.5.2、初始化LoadingCache
复制private static LoadingCache<String, String> loadCache; public static void initLoadingCache() { loadCache = CacheBuilder.newBuilder() // 并发级别设置为 10,是指可以同时写缓存的线程数 .concurrencyLevel(10) // 写刷新,在get时可以同步或异步缓存的时间戳 .refreshAfterWrite(5, TimeUnit.SECONDS) // 写过期,在put时更新缓存的时间戳 .expireAfterWrite(10, TimeUnit.SECONDS) // 设置缓存容器的初始容量为 10 .initialCapacity(10) // 设置缓存最大容量为 100,超过之后就会按照 LRU 算法移除缓存项 .maximumSize(100) // 设置要统计缓存的命中率 .recordStats() // 指定 CacheLoader,缓存不存在时,可自动加载缓存 .build(new CacheLoader<String, String>() { @Override public String load(String key) throws Exception { // 自动加载缓存的业务 return "error"; } } ); }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.3、优化5:通过LoadingCache缓存模板数据,在编辑模板后,更新缓存
查询模板信息后,通过loadCache.put(uuid, pdf);加载到内存中,在编辑模板时,更新缓存过期时间,下次获取模板PDF时,直接从LoadingCache缓存中取,降低数据库访问压力,perfect!!!
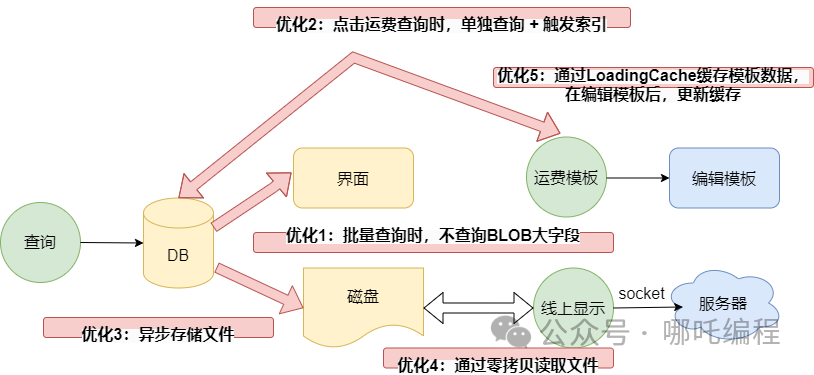
这种情况是不适合缓存的,因为模板pdf本来就是一个BLOB大数据,你把它放内存里缓存了,你告诉我,能放几个?内存扛得住吗?

本文地址:http://www.bzve.cn/news/318d2499657.html
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。