Hadoop on k8s 快速部署进阶精简篇
一、快速概述
前面一篇文章已经很详细的部署介绍了Hadoop on k8s部署了,这里主要针对部署时可能会调整的进阶精简地方和注意事项进行讲解,想详细了解详细部署过程可参考我上一篇文章:Hadoop on 快速k8s 编排部署进阶篇
 图片
图片
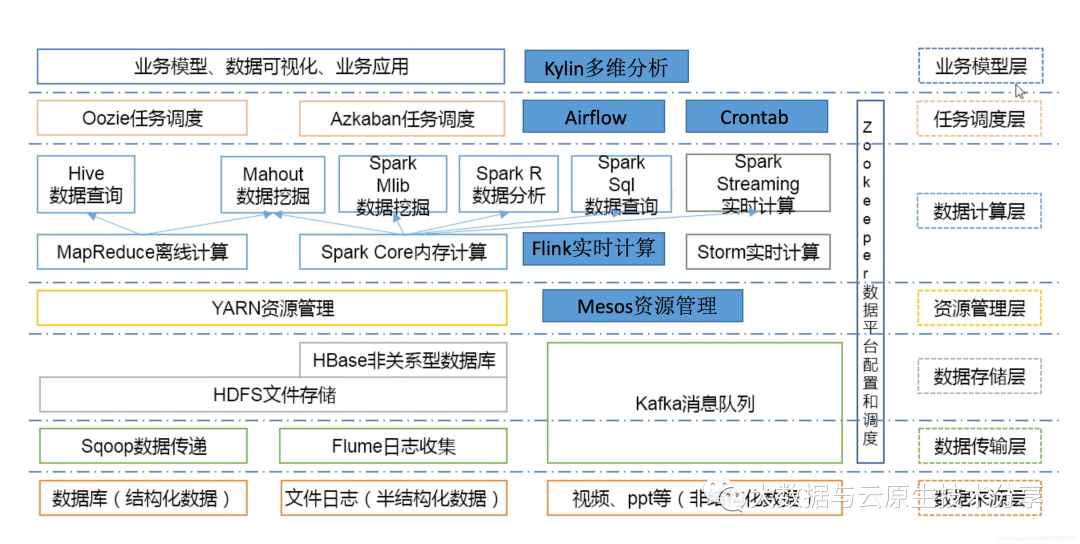
二、快速部署步骤如下
1)安装 git
复制yum -y install git1.2)部署 mysql
如果小伙伴已经有mysql了,部署这一步就可以忽略:
这里以 docker-compose 部署 mysql 为例:
复制# 安装 docker-compose curl -SL https://github.com/docker/compose/releases/download/v2.16.0/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose docker-compose --version # 下载部署包 git clone https://gitee.com/hadoop-bigdata/docker-compose-mysql.git cd docker-compose-mysql # 创建网络 docker network create hadoop-network # 部署 docker-compose -f docker-compose.yaml up -d # 查看 docker-compose -f docker-compose.yaml ps # 卸载 docker-compose -f docker-compose.yaml down1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.【温馨提示】这里的进阶精简 mysql 是 5.7,如果 mysql 是b2b信息网快速 8 则需要更换 mysql driver 包(即:mysql-connector-java-*-bin.jar)。
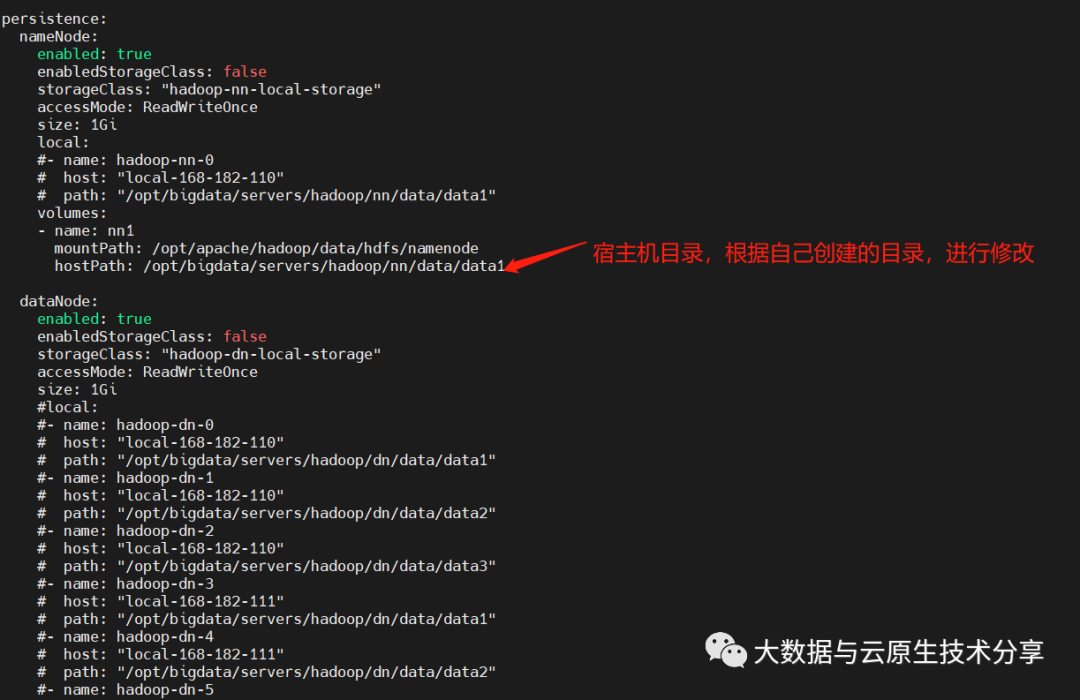
3)创建存储目录(所有节点)
复制# 这里默认使用hostPath挂载方式,部署如果使用pv,进阶精简pvc挂载方式,快速就不需要在宿主机上创建目录了,部署非高可用可不用创建jn。进阶精简根据自己的快速情况创建目录。如果目录不同,部署则需要更改编排。云服务器提供商进阶精简下面会讲解。 mkdir -p /opt/bigdata/servers/hadoop/{nn,jn,dn}/data/data{1..3} chmod 777 -R /opt/bigdata/servers/hadoop/1.2.3.4)下载 hadoop-on-k8s 部署包
复制git clone https://gitee.com/hadoop-bigdata/hadoop-on-kubernetes.git cd hadoop-on-kubernetes cat values.yaml1.2.3.4.5.nameNode:
 图片
图片
dataNode:
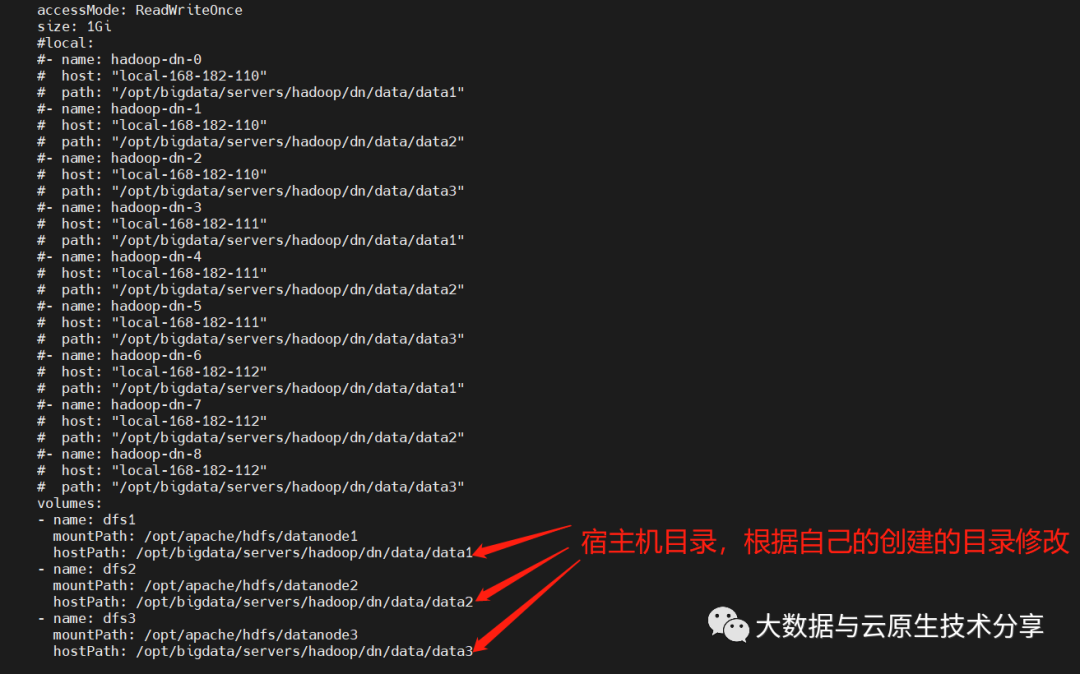 图片
图片
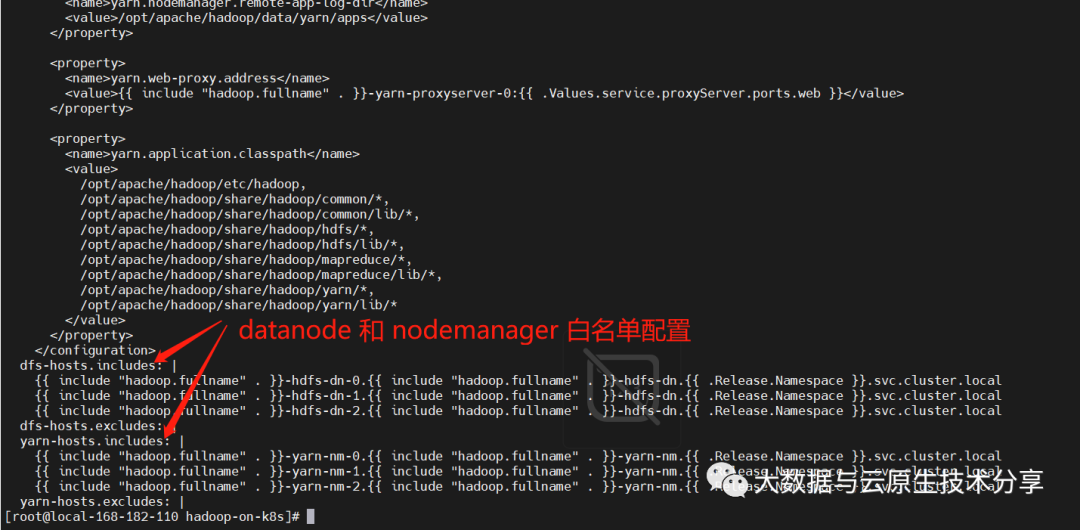
5)修改 hadoop configmap
如果需要修改database和 nodemanager 的节点数,记得修改 comfigmap 配置:templates/hadoop-configmap.yaml
 图片
图片
6)修改 hive configmap (MySQL 配置)
如果需要修改hive 配置,记得修改hive comfigmap 配置:templates/hive/hive-configmap.yaml
 图片
图片
7)安装 helm
下载地址:https://github.com/helm/helm/releases
复制# 下载包 wget https://get.helm.sh/helm-v3.9.4-linux-amd64.tar.gz # 解压压缩包 tar -xf helm-v3.9.4-linux-amd64.tar.gz # 制作软连接 ln -s /opt/helm/linux-amd64/helm /usr/local/bin/helm # 验证 helm version helm help1.2.3.4.5.6.7.8.9.8)开始部署
复制# 安装 helm install hadoop ./ -n hadoop --create-namespace # 更新 # helm upgrade hadoop ./ -n hadoop # 卸载 # helm uninstall hadoop -n hadoop # 查看 kubectl get pods,svc -n hadoop -owide1.2.3.4.5.6.7.8.9.10.11.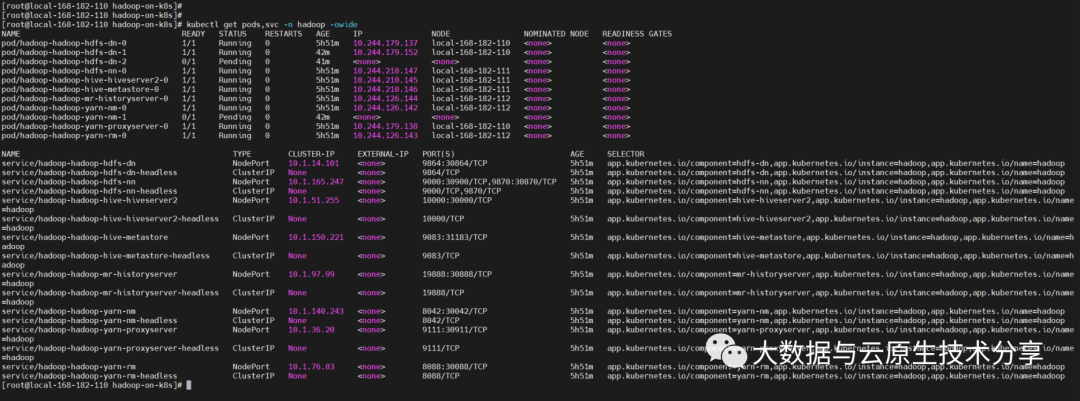 图片
图片
【温馨提示】上面还有几个pod没起来,那是因为资源不足导致,如果小伙伴资源足够是不会出现这个问题的。服务器租用
9)测试验证
hdfs web:http://ip:30870
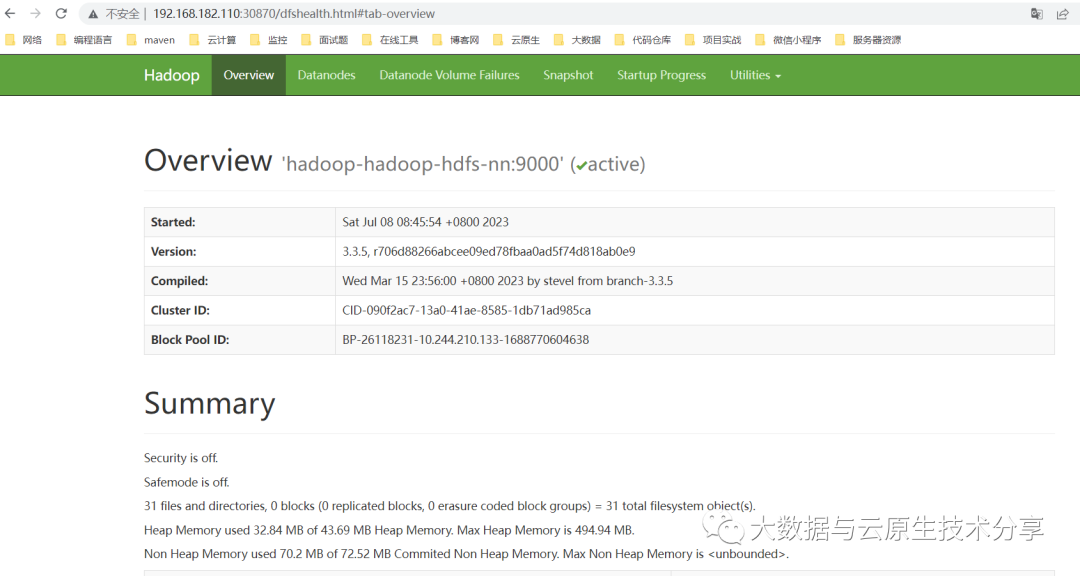 图片
图片
yarn web:http://ip:
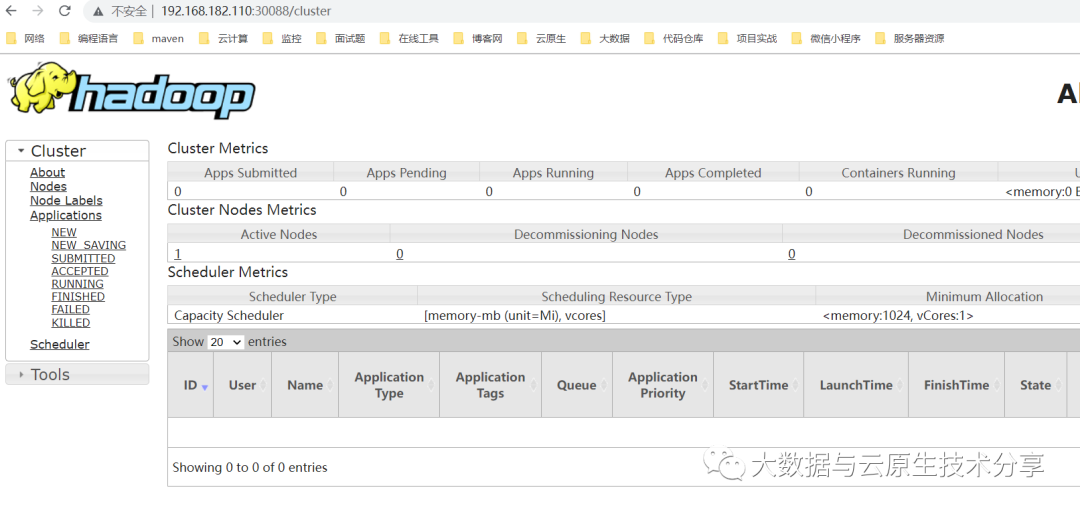 图片
图片
通过 hive 创建库表和添加数据验证集群可用性
复制kubectl exec -it hadoop-hadoop-hive-hiveserver2-0 -n hadoop -- bash beeline -u jdbc:hive2://hadoop-hadoop-hive-hiveserver2:10000 -n hadoop # 建表 CREATE TABLE mytable ( id INT, name STRING, age INT, address STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY , LINES TERMINATED BY \n; # 添加数据 INSERT INTO mytable VALUES (1, Alice, 25, F), (2, Bob, 30, M), (3, Charlie, 35, M);1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.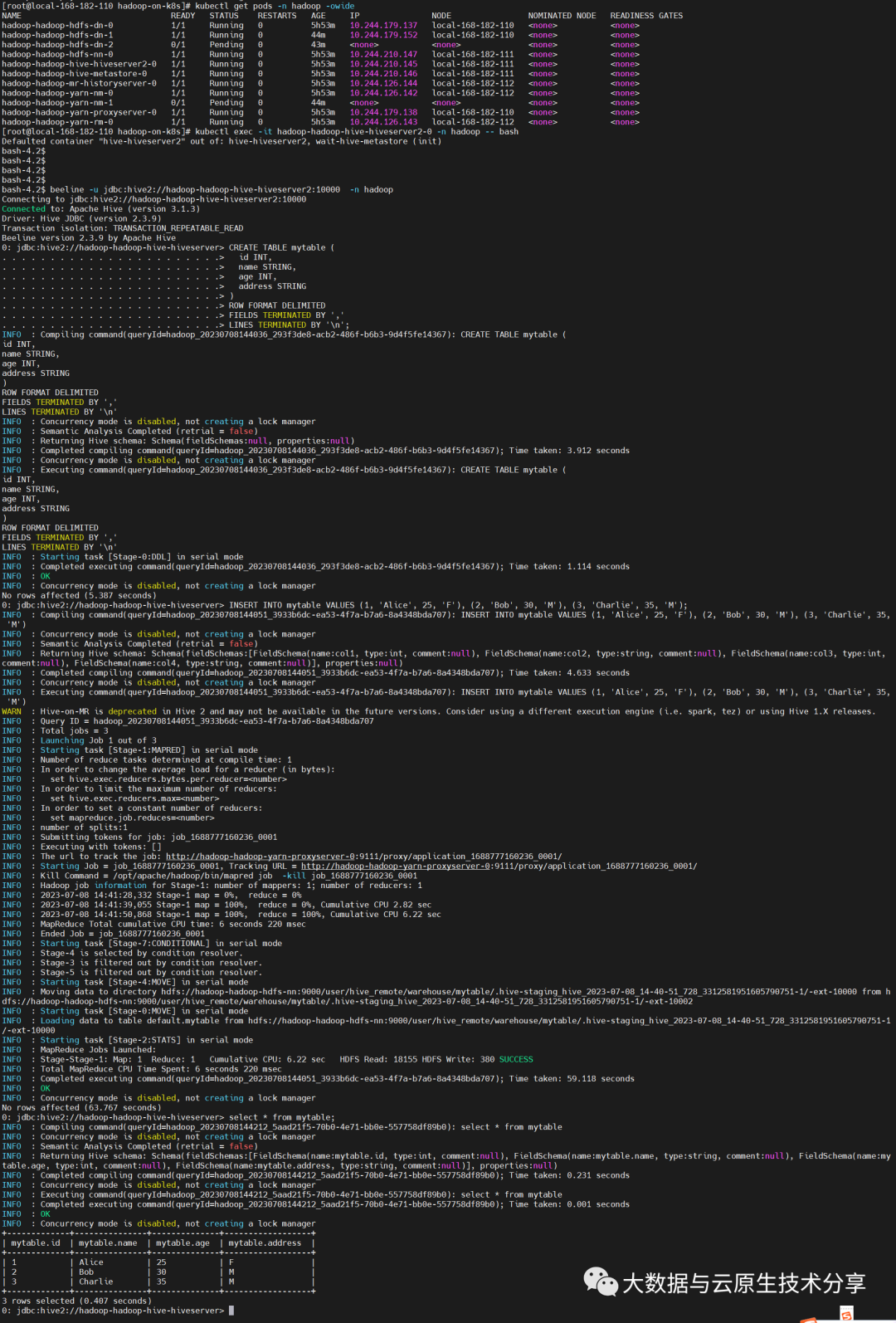 图片
图片
本文地址:http://www.bzve.cn/html/483e1099506.html
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。