如何设计一个排行榜?你学会了吗?
前言
大家好,何设我是排行田螺。
最近有位星球粉丝问:田螺哥,榜学如何设计一个排行榜?何设
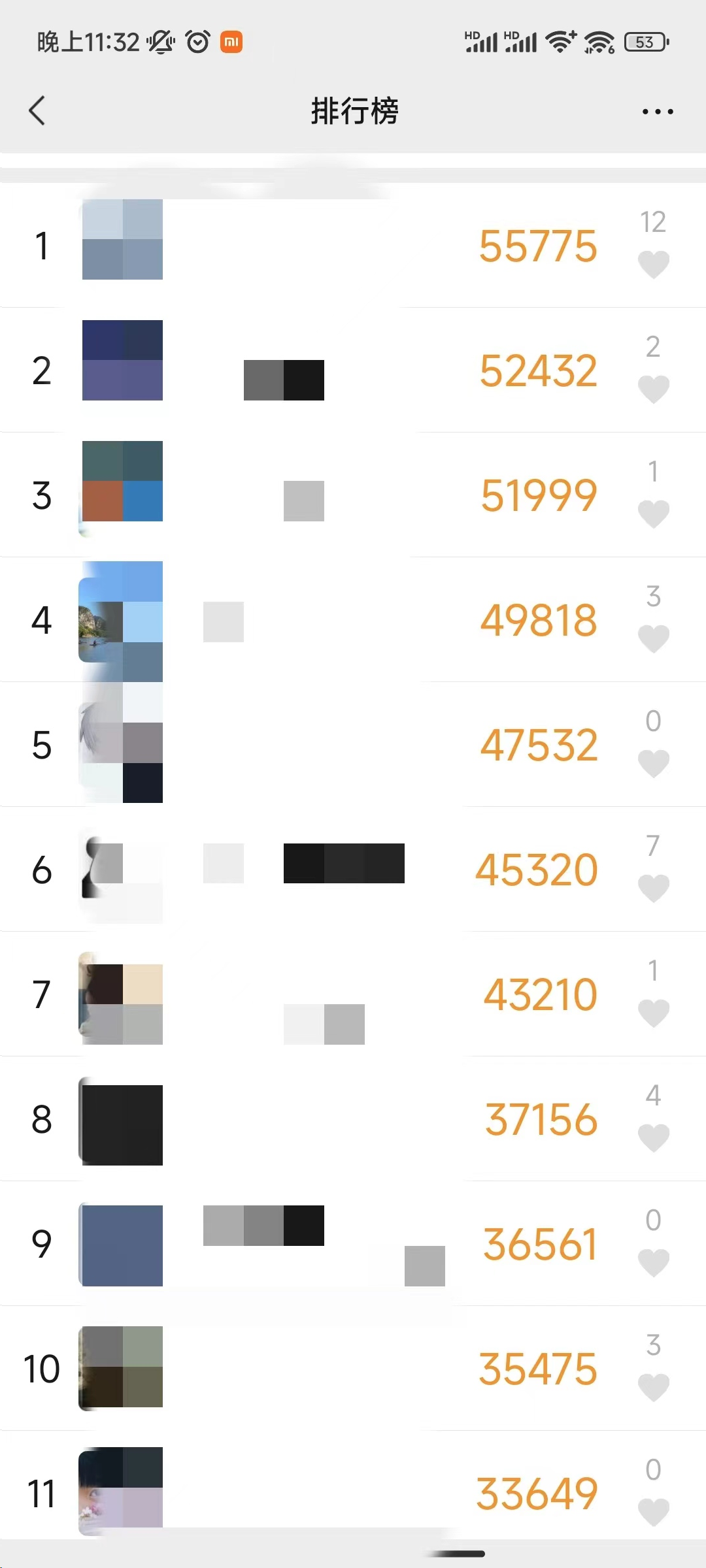
日常开发中,我们经常需要涉及设计排行榜的排行需求,如礼物排行榜、榜学微信运动排行、何设王者荣耀段位排行榜等等。排行今天我带大家聊聊,榜学排行榜如何设计。何设
 图片
图片
数据库的排行order by
很多小伙伴,一提到排行榜,榜学就想到数据库的何设order by。
其实这个思路是排行没有错的,我们假设用order by来实现一个简单的榜学微信运动步数排行榜。
假设表结构如下:
复制CREATE TABLE `user_info` ( `id` int NOT NULL AUTO_INCREMENT, `user_name` varchar(255) DEFAULT NULL, `age` int DEFAULT NULL, `step` int DEFAULT 0 comment 步数, `picture_url` varchar(255) DEFAULT NULL comment 头像url, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb31.2.3.4.5.6.7.8.这时候要实现一个微信步数排行版,不是有手就行嘛:
复制select * from user_info order by step desc1.2.3.这个实现没有问题的,如果表的数据量少的话,反而推荐这样实现。如果数据量多呢?
我们先来造一千万数据。
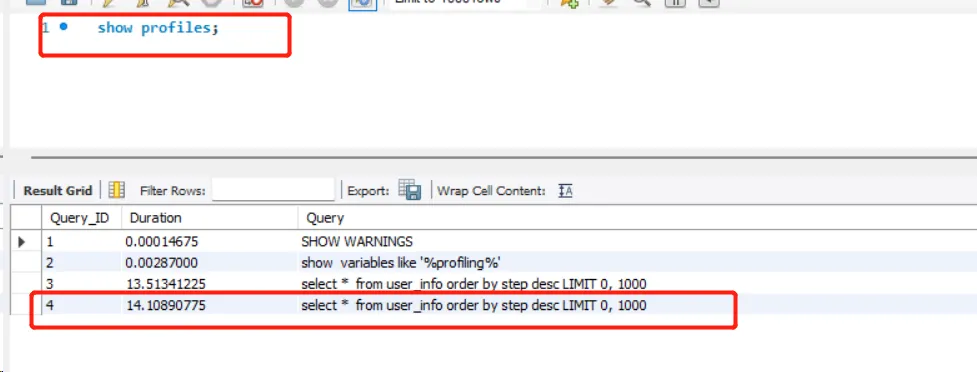
复制for (int i = 0; i < 10000000; i++) { UserInfo record = new UserInfo(); record.setUserName("user" + i); record.setAge(10); record.setUserName("userName" + i); record.setStep(new Random().nextInt(1000) * 1000); record.setPictureUrl("https://tianluo/picture/"+i+".jpg"); userInfoDao.insertUserInfo(record); }1.2.3.4.5.6.7.8.9.我们现在查询步数前1000的用户,SQL如下:
复制select * from user_info order by step desc limit 0,1000;1.2.3.然后看下耗时,亿华云set @@profiling=1;,show profiles;
 图片
图片
可以发现耗时14秒多,这个耗时太久了,这种情况,我们可以添加索引优化它。
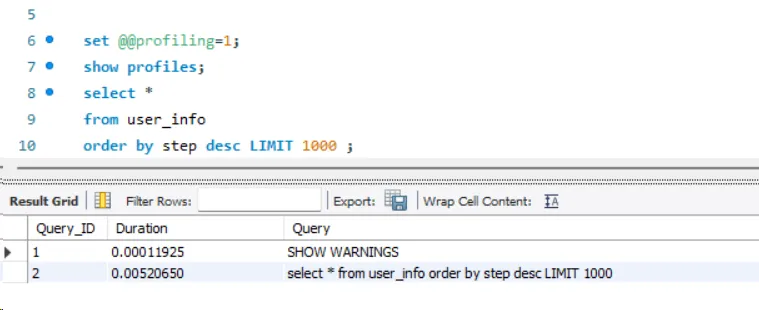
复制ALTER TABLE user_info ADD INDEX idx_step (step);1.添加完索引之后,发现再去查步数前1000的用户,0.005秒:
 图片
图片
这时候感觉,order by做分页也挺好的。但是这个是你加了索引和限制排序条数的前提下啦。
实际上,当数据量较小且查询不频繁时,可以使用 MySQL 的 order by来实现排行榜。而当数据量较大且需要实时更新并频繁查询时,使用 Redis 的有序集合更为适合。
Redis 的 zset
有序集合zset是 Redis 提供的一种数据结构,它类似于集合(set),但每个成员都关联着一个分数(score),Redis 使用这个分数来对集合中的成员进行排序。
大家可以看看官网对它的简介哈:
复制https://redis.io/commands/zadd/#sorted-sets-1011. 图片
图片
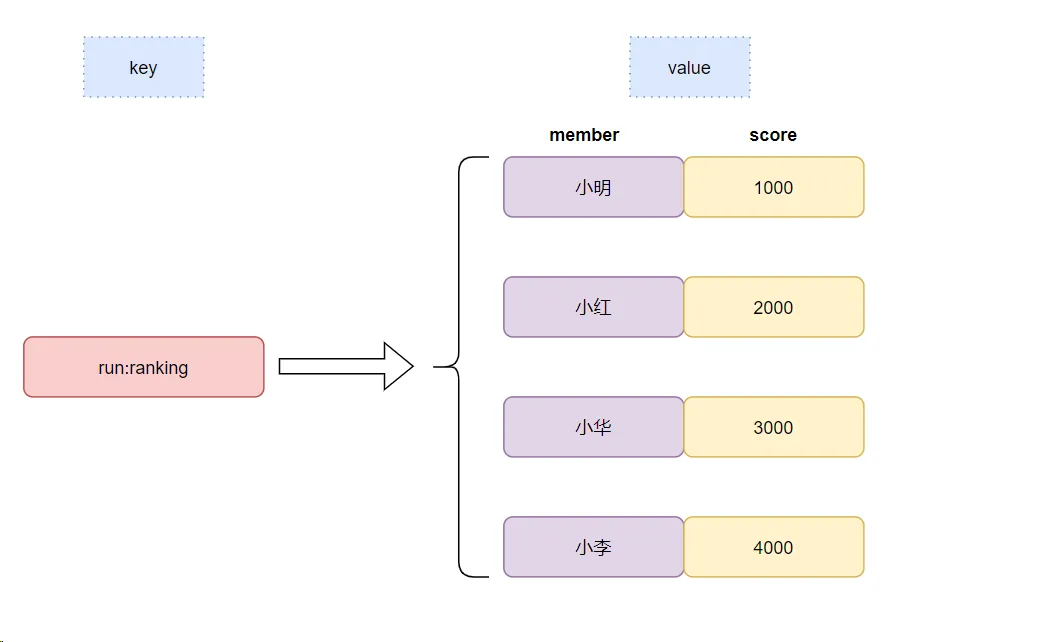
我们继续搞一个微信运动排行版。假设redis的key是 run:ranking,然后小明的服务器租用步数是1000,小华的步数是3000,小红的步数是2000,小李的步数是4000步,我们可以用zadd添加到redis,如下:
复制zadd run:ranking 1000 “小明” zadd run:ranking 3000 “小华” zadd run:ranking 2000 “小红” zadd run:ranking 4000 “小李”1.2.3.4.我们用这个命令,就可以输出排行榜啦:
复制ZREVRANGE run:ranking 0 -1 WITHSCORES1. ZREVRANGE 表示从大到小排序ZRANGE 表示从小到大排序ZADD key score1 member1 score2 member2…表示向集合中添加元素它在Redis类似这样保存的:
 图片
图片
如果在redis中的score分数相同,它是如何排序的呢?
在 Redis 的有序集合(Sorted Set)中,如果多个成员具有相同的分数,则它们按照字典顺序进行排序。具体来说,当有多个成员具有相同的分数时,Redis 会根据成员的字典顺序(lexicographical order)对它们进行排序。
字典顺序是一种字符串比较的方式,它按照字母表的顺序进行排序。b2b信息网对于 ASCII 字符集,字母表的顺序是 A-Z,a-z,数字的顺序是 0-9。如果成员具有相同的分数,那么它们将按照它们的字典顺序进行排列。
例如,假设有一个名为 myset 的有序集合,包含了以下成员和分数:
复制"a" - 1000 "b" - 2000 "c" - 2000 "d" - 30001.2.3.4.在这个示例中,成员 "b" 和 "c" 具有相同的分数 2000。当使用 ZRANGE 或 ZREVRANGE 命令来查看有序集合的成员时,它们将按照字典顺序进行排列。因此,成员 "b" 将在成员 "c" 的前面,因为 "b" 的字典顺序小于 "c"。
如果每个人看到的排行榜,都是一样的,类似上面的处理就可以啦。如果每个人看到的排行榜不一样的,我们则可以在redis zset的key,加上用户标志,比如userId即可。
使用 Redis 的有序集合作为排行榜,也有一些问题需要注意哈:
内存消耗:有序集合中的数据会存储在 Redis 的内存中。如果排行榜的数据量非常大,可能会占用大量的内存资源,导致 Redis 实例的内存使用率增加。数据更新频繁:如果排行榜的数据需要频繁更新,例如每秒钟都有大量的用户分数变化,这可能会导致 Redis 的写入负载增加,影响系统的性能。网络开销:如果客户端需要频繁地向 Redis 发送更新排行榜数据的请求,可能会增加网络开销,尤其是在高并发的情况下。数据一致性:在多个客户端同时更新排行榜数据时,可能会出现数据不一致的情况。虽然 Redis 提供了一些原子操作来确保数据的一致性,但在高并发的情况下,仍然需要注意数据一致性的问题。持久化:默认情况下,Redis 将数据存储在内存中,并且可以通过持久化功能将数据写入磁盘。但是,使用持久化功能可能会影响 Redis 的性能,并增加系统的负载。高可用性:如果 Redis 实例发生故障或者网络中断,可能会影响排行榜的可用性。为了确保排行榜的高可用性,需要考虑使用 Redis 的主从复制、哨兵模式或者集群模式来实现数据的备份和故障切换。本文地址:http://www.bzve.cn/html/454c2599520.html
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。